A model is a neural network already trained for a purpose (a certain output); it has certain inputs or prompts.
The prompt is the stimulus or instruction you give it to use that knowledge in a specific way.
A prompt is any text, image, or data that you give to an AI model to get a response.
If you type the word “Java,” the prompt triggers weights related to programming, coffee, or the Indonesian island. Depending on how you follow the prompt (“Java code for a Trie”), the AI will filter its knowledge to respond only with relevant information.
- The Model is the library or executable (it’s already compiled and has the functions ready)
- The Prompt consists of the arguments or parameters you pass to the main function to execute a specific task
Since prompts are processed as “tokens” (pieces of words), each word you type consumes a little of the model’s temporary memory while it responds to you.
Not all prompts are the same.
- User Prompt: What you type in the chat (“How do I commit in Git?”)
- System Prompt (or System Message): This is an “invisible” instruction that the developer configures before the user speaks. For example: “You’re a backend expert who responds concisely and with humor.” The model follows this throughout the session
- Negative Prompt: This is widely used in image generation to tell the AI what we don’t want (e.g., “don’t include people”)
prompt types:
- Zero-shot: You ask it to do something directly without examples
- Few-shot: You give it a couple of examples before asking it to do the task (“Translate: Dog -> Dog, Cat -> Cat, Bird -> …”)
- Chain of Thought: You ask it to “think step by step.” This forces the model to use its logical reasoning before giving the final answer
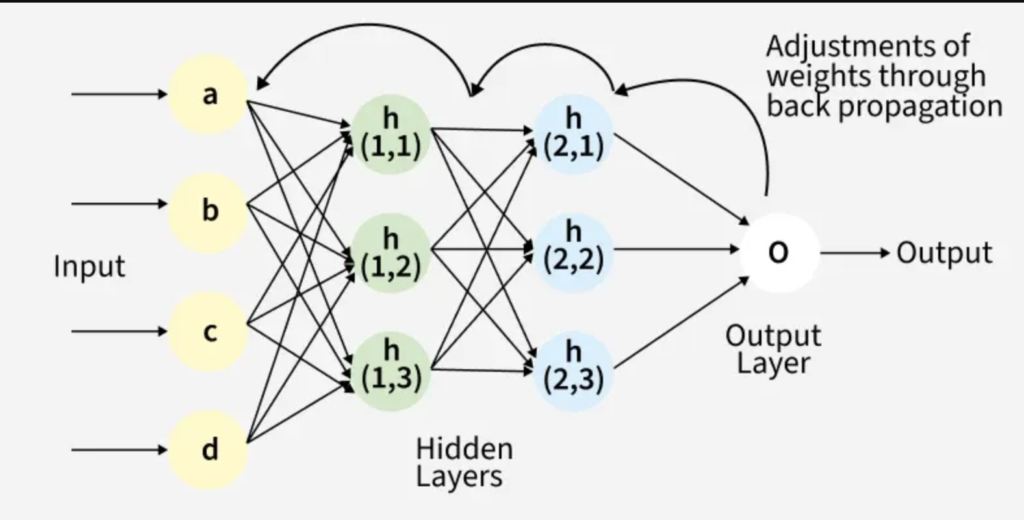
A neural network is a specific type of algorithm inspired by the human brain. Imagine it as the “skeleton” or blueprint of a building. By itself, before being trained, it’s just a structure of layers and connections with random values.
Training is the process of exposing that network to thousands of data points. During this process, the network adjusts its “weights” (the strength of the connections between neurons) through mathematical operations. Once this process is complete and the network “knows” what to do, what you get is the model.
Are there models that aren’t neural networks?
Yes.
Although neural networks (especially deep learning) dominate current AI, there are other types of machine learning models that aren’t neural networks, such as:
- Decision Trees: Classify data using “if this happens, then that happens” rules.
- Linear Regressions: Simple mathematical models for predicting numerical values.
- Support Vector Machines (SVMs): Used to categorize groups of data.
Almost all modern and powerful AI models (such as ChatGPT or Midjourney) are trained neural networks. However, in the world of computing, a model can be any algorithm that has “learned” from data, whether it’s a neural network or a more traditional statistical method.
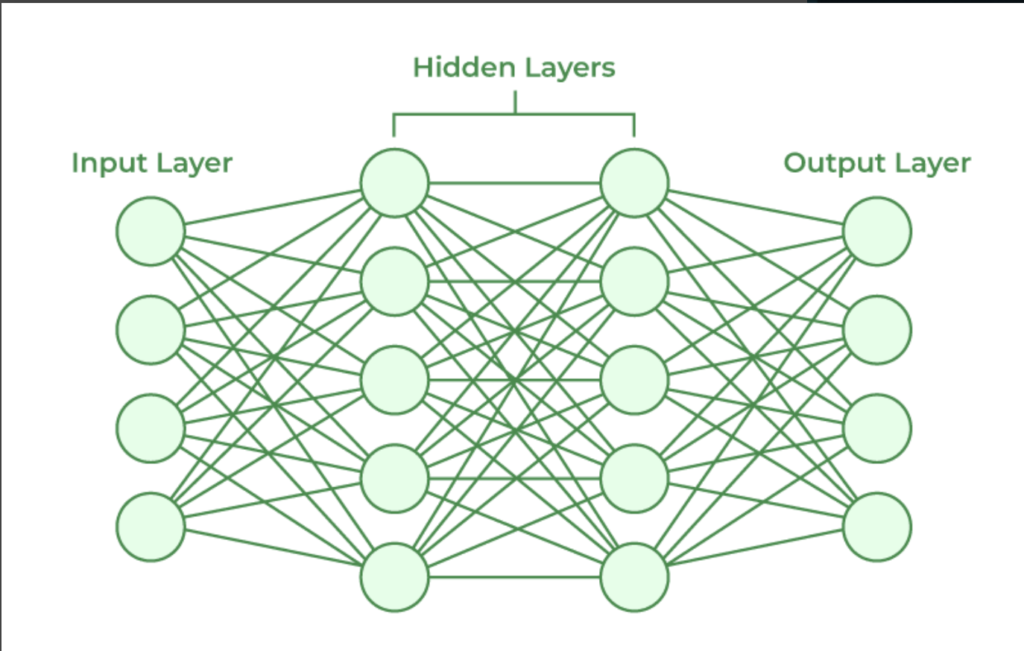
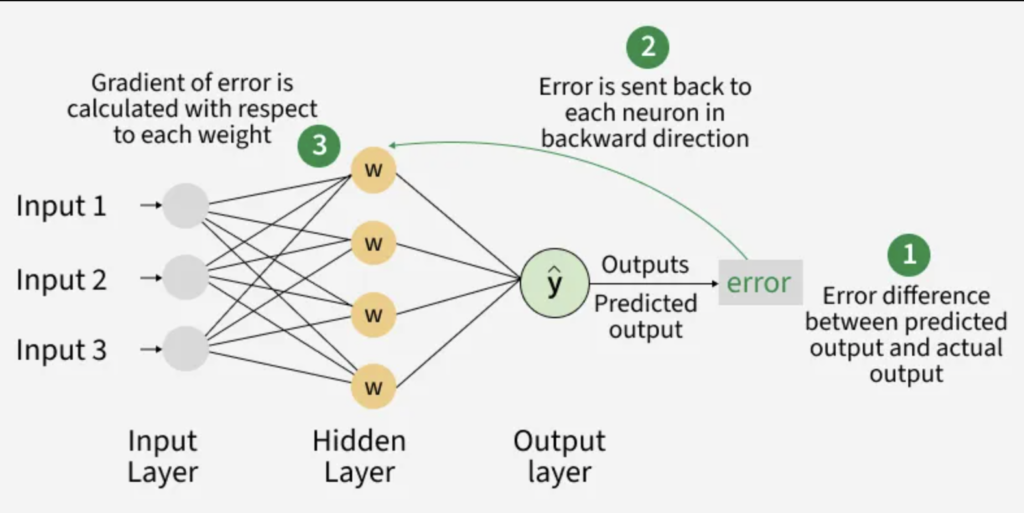
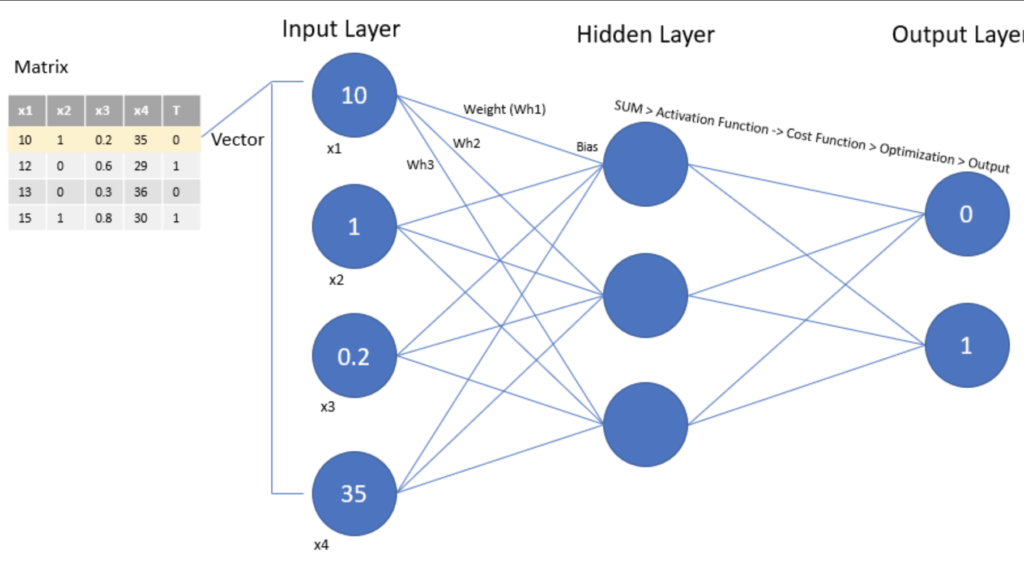
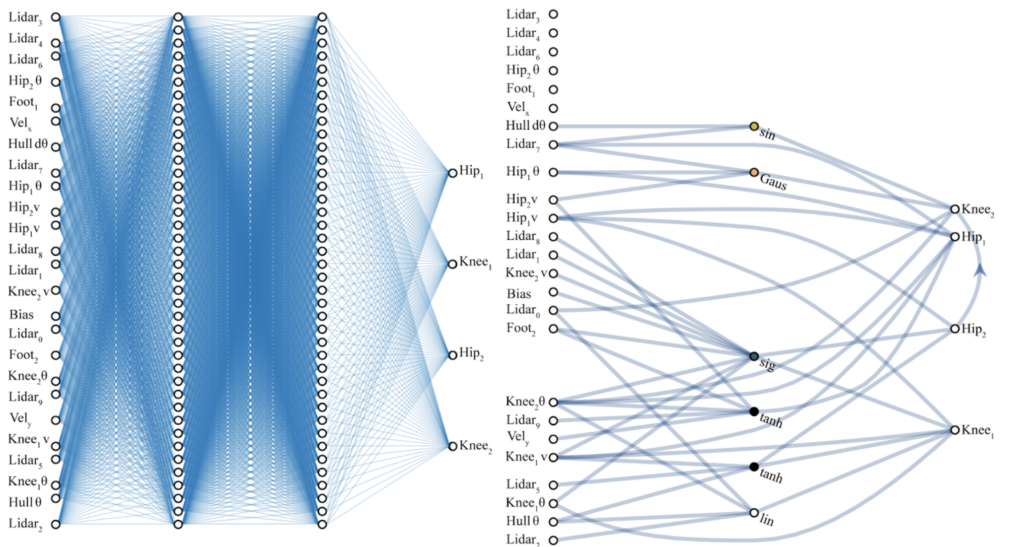
The input layer contains the input parameters, the hidden layer handles the data processing, and the output layer is the result returned from n parameters (the prediction); think of it as a mathematical function
This is what in computer science is called a graph; there are n layers that have m nodes, each node in one layer interacts with all the nodes in the next layer.
A model is a pre-trained neural network; it consumes a lot of energy because it’s like many if statements.
That leads to a lot of processing, a lot of decisions
bias
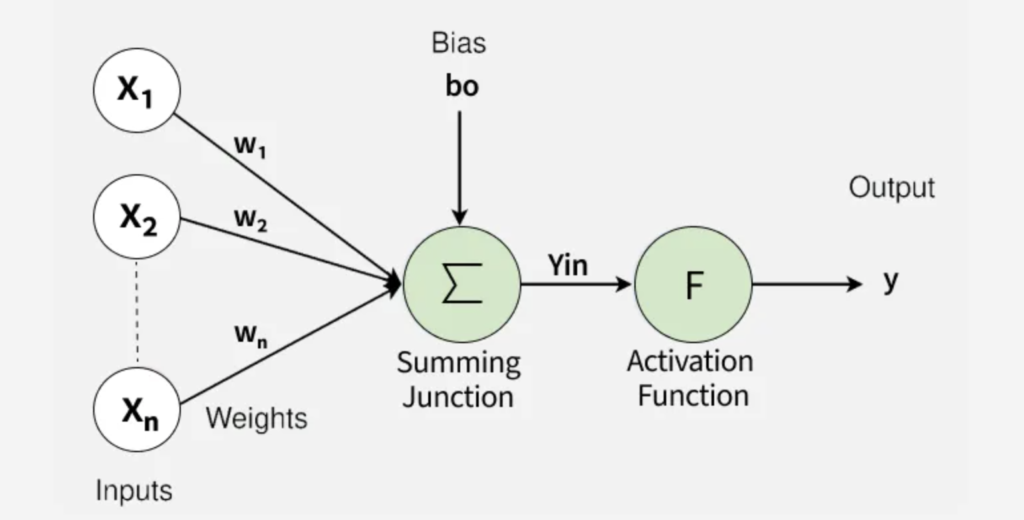
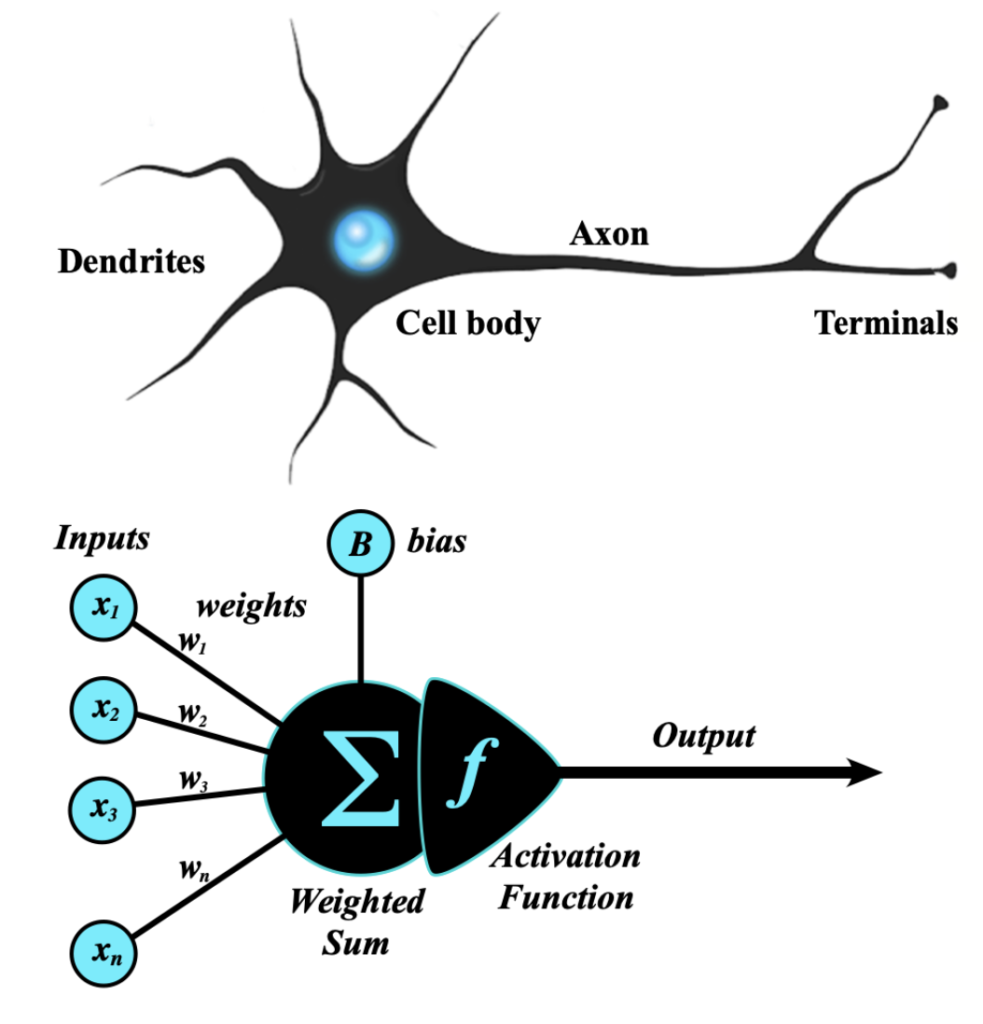
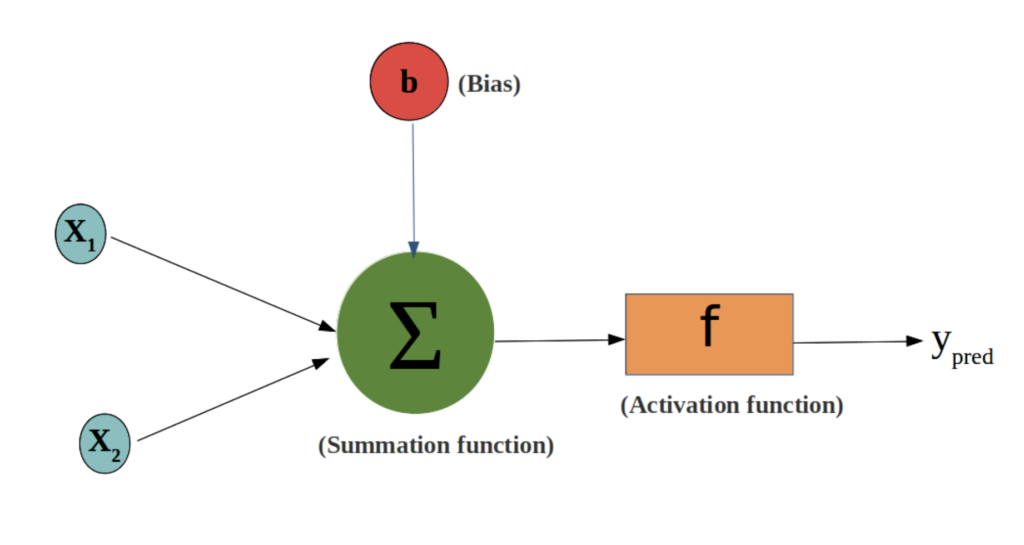
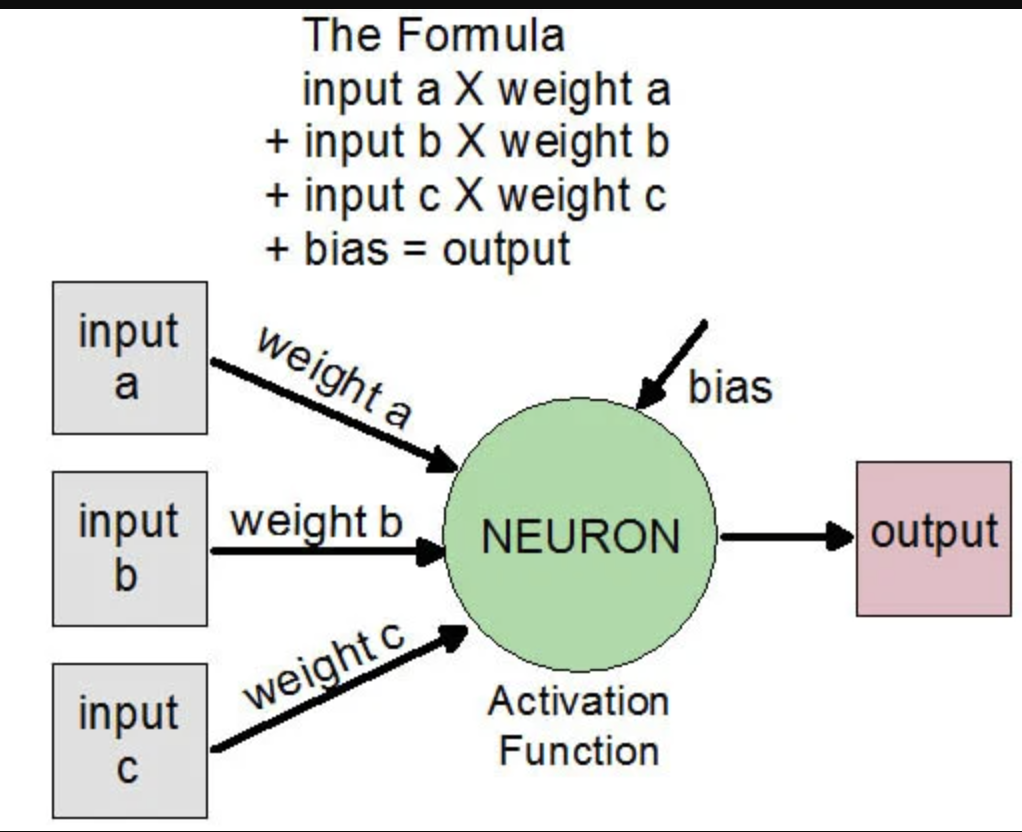
Bias is a constant value that adds variability or mutation (in biology), as in real life
Bias is another number that helps adjust the final result. If the resulting number is high enough, the neuron “turns on” and sends the signal to the next layer.
weights
Sometimes the “weights” of the model are referred to as the physical file that contains what has been learned.
They are, in essence, the “knowledge” of artificial intelligence. If the neural network is the structure of wires and light bulbs, the weights are the knobs that control how much electricity passes through each wire.
Data travels from one layer to another through connections. Each connection has a weight, which is simply a number (for example: $0.5$, $-1.2$, or $0.003$).
- High weight: This means that the information is very important to the final result
- Low weight (close to zero): This means that the information is almost irrelevant
- Negative weight: This means that the information “subtracts” from or inhibits the result (like a brake)
When the model is created, the weights are completely random. The model is “dumb”: if you show it a picture of a cat, it will say it’s a washing machine because its weights don’t make sense.
The training consists of adjusting those numbers:
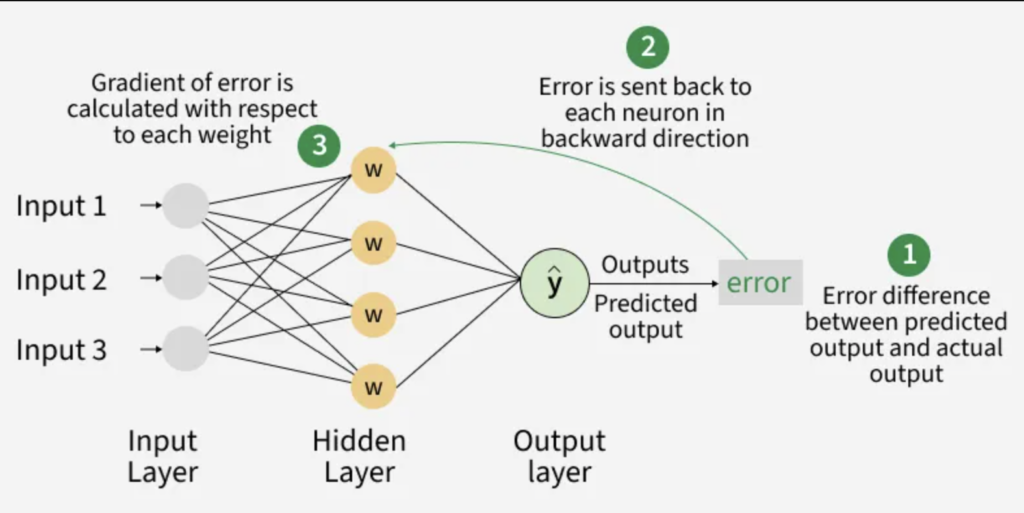
- The model makes a prediction (using its current weights)
- It calculates how wrong it was (using a loss function)
- It uses an algorithm called backpropagation to go back and say, “Hey, this connection was responsible for the error, let’s reduce its weight”
When you hear that a model like Llama or GPT has “70 billion parameters”, they are referring almost entirely to the number of weights it has stored in its memory.
- Each parameter is a decimal number that must be stored
- That’s why large models require so much RAM or VRAM: you have to load those trillions of numbers to be able to multiply your data by them in milliseconds
Weights define patterns. If a language model knows that “days” usually follows the word “Good,” it’s because the weight of the connection between those two ideas in its network is very high.
Weights are like the configuration variables of a system, with the difference that they are not written by a human, but the system finds them on its own through pure statistical calculation.
The weights are the “frozen” knowledge inside the AI brain
trainning
Normally, the model has already learned and is “frozen”.
Training Phase (The model learns):
During this stage, the model is like a student at university. It is fed millions of data points, makes mistakes, corrects them, and adjusts its internal parameters. At the end, a final file is generated. That file is the trained model.
Inference Phase (The model applies what it has learned):
When you use an AI (like ChatGPT or a search engine), the model is in inference mode. Here, the model is not modifying its internal connections; it simply uses what it already knows to process your question.
The student is no longer studying the book; he is only answering with what he remembers.
- Fine-tuning: If the model creators find that it has become outdated, they can take the “frozen” model and give it an extra training session with new data. This creates a new version of the model
- Contextual Learning: When you give AI instructions or data in a chat, it seems to “learn” your preferences. But this is temporary. As soon as you log out or clear your history, the model reverts to its original state. It hasn’t permanently stored that information in its “brain”
- Continuous Learning (Online Learning): Some experimental or highly specific models do adjust their parameters in real time as they receive data. However, in commercial AI (large language models or image generators), this is not usually done because it is very expensive and the model could become unstable or corrupted by bad data
The brain has an amazing balance. We can learn a new word today without forgetting how to ride a bike or how to program in Java.
However, if you try to teach something new to a “frozen” AI model without proper precautions, Catastrophic Forgetting occurs: the model adjusts its weights for the new information and suddenly “erases” what it knew before.
- The Brain: It learns from very few examples. If you see a strange animal just once, you’ll probably recognize it for the rest of your life
- AI: It needs thousands or millions of examples of the same object to “understand” the patterns of its pixels
For an AI model to learn constantly like we do, it would need to be in a perpetual state of training.
Imagine that every time you talk to someone, your brain had to consume the energy of a small city to process the information.
In software engineering, we prefer the Training + Inference approach. It’s more efficient to separate the “study” from the “application.”
There are techniques that attempt to approach that “constant slowness” of the brain, such as Online Learning (where the model is updated with each piece of data that comes in) or periodic Fine-tuning.
Why don’t they learn all the time?
- Cost: Training large models requires thousands of processors running for weeks. Doing so in real time would be prohibitively expensive
- Catastrophic Forgetting: If an AI tries to learn something new very quickly, it sometimes mistakenly “erases” basic concepts it already knew
- Security: If the model learned from each user, someone could “teach” it offensive or incorrect things on purpose
Lifelong Learning
That is the great challenge of Continuous AI. The human brain has biological mechanisms to protect old memories while integrating new ones, something that is extremely difficult to replicate in computing without the model “breaking.”
Replay Buffer
To prevent the AI from forgetting previous information when learning something new, it is “reminded” of old data from time to time.
You keep a small sample of the old data, and each time you teach them something new, you mix in a little of the old so they don’t lose their touch. It’s like you’re studying a new topic but also doing a quick review of what you learned last month.
Regularization (EWC – Elastic Weight Consolidation)
It identifies which “neurons” (weights) are vital for tasks already learned and makes them more “rigid” or difficult to change. Thus, the model only uses neurons that “aren’t doing anything important” to learn new information.
Dynamic Architectures
Instead of having a fixed-size model, the system grows.
If the model detects that new information is very different from what it already knows, it adds new layers or neurons to its structure. It’s as if the brain could manufacture extra gray matter on demand when you decide to learn a new language.
If we can make an AI learn like a human (slowly, but steadily and without forgetting), we wouldn’t have to spend millions of dollars “retraining” models from scratch every time the world changes.
a spanish video: